


Organizations invest millions in AI models and cloud infrastructure. Yet, many overlook the single factor that determines whether those investments soar or sink: the integrity of the underlying data.
Poor data quality is a “silent killer.” It doesn’t usually appear as a line item on a balance sheet, but it manifests as operational friction, flawed forecasts, and missed market opportunities. For leaders aiming for peak efficiency, fixing the data foundation is no longer optional—it is a strategic mandate.
1. The “Data Janitor” Trap: Wasted Operational Hours
When data is inconsistent or fragmented, your most expensive assets – Data Scientists and Analysts – spend up to 80% of their time simply cleaning and reconciling records.
This “invisible drain” slows down every department:
- Finance: Spending days manually reconciling transactions across disparate systems.
- Sales: Chasing leads with outdated contact information or duplicate profiles.
- Operations: Managing supply chain delays caused by incorrect inventory tagging.
By partnering for example with Addepto for specialized data engineering services, organizations can automate these cleaning processes, shifting the focus from “fixing data” to “finding insights.” (check: https://addepto.com/data-engineering-services/)
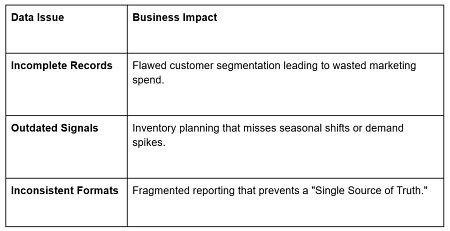
2. The “Garbage In, Garbage Out” Decision Cycle
Even the most sophisticated AI tool will produce misleading results if the input is flawed. This creates a dangerous scenario where leaders make high-stakes decisions based on “credible-looking” but fundamentally broken data.
Key Insight: A decision made 20% faster is a liability if the data is 30% inaccurate. Precision is the prerequisite for speed.
3. Customer Trust: The Non-Financial Cost
In an era of hyper-personalization, poor data is a brand risk. When a customer receives three different marketing emails due to duplicate records, or when a support agent can’t see a customer’s full history, trust erodes.
High-quality data allows for a seamless, “small company” feel even at an enterprise scale. Without it, your customer experience becomes as fragmented as your databases.
How to Fix the Foundation: Roadmap
Fixing data quality isn’t about a one-time “cleanup”; it’s about building a resilient architecture. Organizations like Addepto help organizations move from data chaos to data excellence through a structured approach:
- Data Audits & Profiling: Using automated tools to find duplicates, missing values, and structural “rot” in your current systems.
- Robust Data Pipelines: Implementing modern data engineering that validates and cleans data in real-time as it moves from source to storage.
- Governance Frameworks: Establishing clear ownership and standards so data stays clean as the company scales.
- Single Source of Truth: Consolidating fragmented silos into a unified data warehouse or lakehouse architecture.
Conclusion: Data Quality as a Competitive Edge
While poor data quality creates hidden costs, high-quality data creates a multiplier effect. It allows you to deploy AI with confidence, react to market shifts in real-time, and out-maneuver competitors who are still stuck reconciling spreadsheets.
Data quality is not a technical chore – it is a strategic asset. Organizations that invest in their data foundation today are the ones that will lead the AI-driven markets of tomorrow.